Does GPT-2 Represent Controversy? A Small Mech Interp Investigation
In thinking about how RLHF-trained models clearly hedge on politically controversial topics, I started wondering about if LLMs would encode these politically controversial topics differently than topics that are broadly considered controversial but not political. And if they do, to understand if the signal is already represented in the base model, or if alignment training may be creating/amplifying it.
To test this, I assembled a list of 20 prompts, all sharing the same "[Thing] is" structure, such as "Socialism is" and "Cloning is". The aim was to have 5 prompts each from 4 groups: politically controversial, morally controversial, neutral abstract, and neutral concrete. I used TransformerLens on GPT-2 to conduct this research, focusing on residual stream activations. GPT-2 was chosen as it is an inspectable pure base model with no RLHF, in addition to the fact I'm limited in my access as an independent researcher.
I'd like to flag up top that this is independent work that is in the early stages, and I would love to get feedback from the community and build on it.
At the simplest as a starting point, I ran each of these prompts and looked through the most probably following token, which did not yield anything of interest. Next I computed the cosine similarity between every pair of prompts, which also did not prove to be a fruitful path as the similarity was too high across all pairs to offer anything.
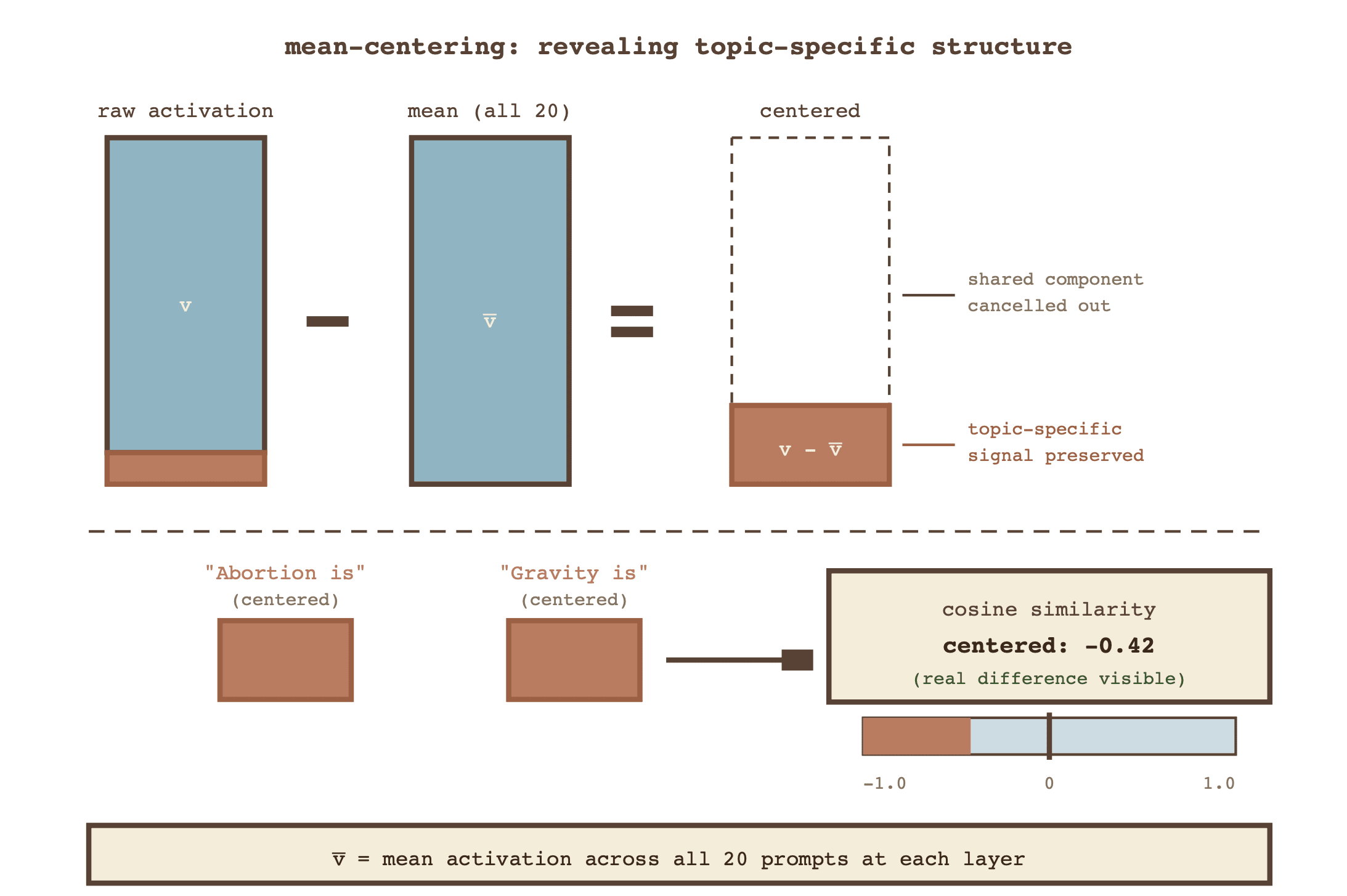
The breakthrough after hitting this wall proved to be subtracting the mean activation at position -1 of each prompt. I suspected that the common structure shared by each prompt ("[Thing] is") seemed to be the primary driver of similarity, obscuring any ability to investigate my initial question. By mean-centering the prompts, I was able to effectively eliminate, or at least significantly diminish, this shared component to limit potential disparity to only our differentiated first word.
Categorical structure did emerge after mean-centering. The layer 11 (last layer in GPT-2) mean-centered similarity matrix did seem to show signs of grouping, which was encouraging, though not strictly in line with my hypothesis of a 'controversy' axis driving this grouping. The primary axis seemed to instead be abstract-social vs. concrete-physical. Next-token predictions were undifferentiated regardless, however.
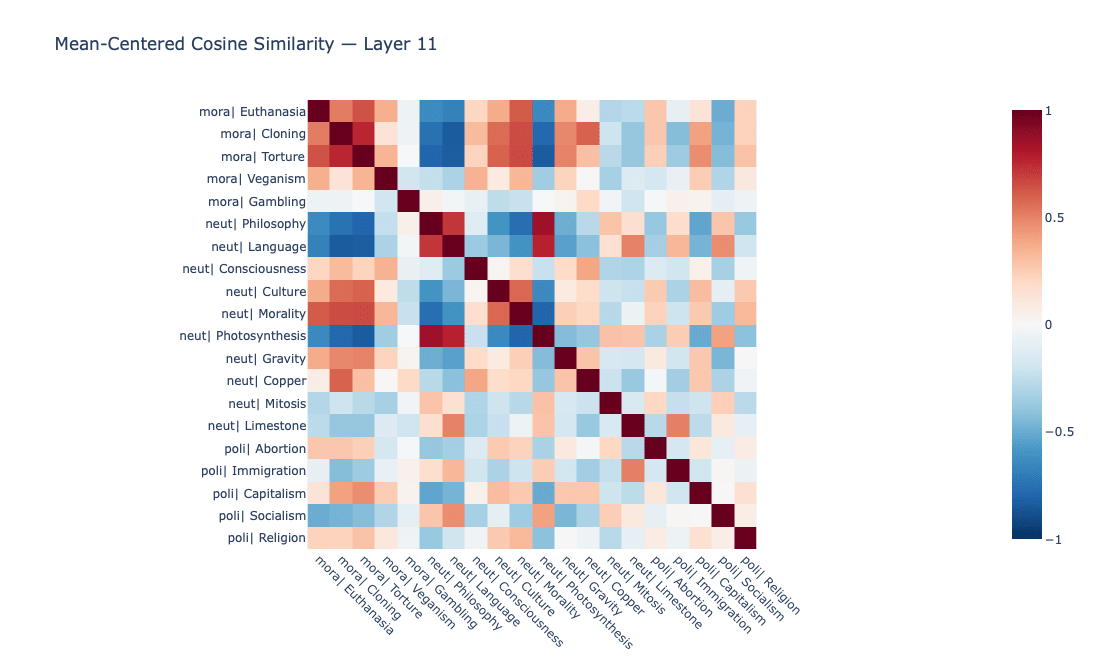
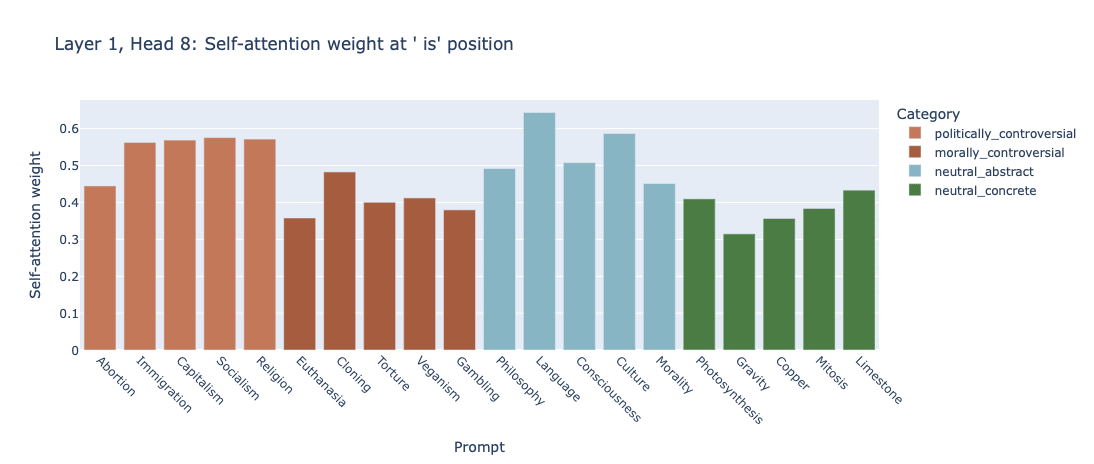
Speculating about these results, I'm hypothesizing that GPT-2 may organize more around ontological categories rather than pragmatic/social properties. This makes sense to me intuitively: An LLM would be considering a "[Thing] is" prompt to be more like the start of a wikipedia article than the start of a reddit comment about a political opinion on the topic. If this is the case, it makes me wonder if RLHF may be constructing a controversy axis in some cases rather than finding one that already exists. Another possibility, at least for users interacting with LLMs via consumer channels, is that the hedging is just baked in via the system prompt more than anything else.
To state the significant limitations of this work, certainly I'd start with the n=5 sample for each category being on the small side, and I do plan to replicate this experiment with a larger, and perhaps more rigid, sample. There is also the potential impacts of tokenization confound, and the obvious prompt format constraints. For one example, though the prompts were all the same amount of words, the amount of tokens ranged mostly between 3-5.
To build on this work, I think my next steps may be repeating the experiment with more prompts, as well as repeating similar testing on different models to see if the theory about the primary axis holds. I'd be especially curious to assess if RLHF has any impact on categorization along this axis.
Please let me know any thoughts you have, I'm eager to get feedback and discuss.
Discuss